Publications
2026
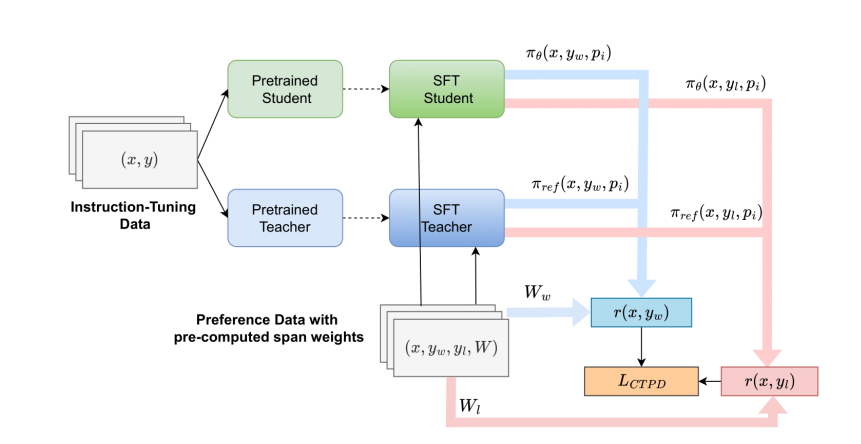
- CTPD: Cross Tokenizer Preference DistillationTruong Nguyen*, Phi Van Dat, Ngan Nguyen, and 3 more authorsProceedings of the AAAI Conference on Artificial Intelligence, 2026
While knowledge distillation has seen widespread use in pre-training and instruction tuning, its application to aligning language models with human preferences remains underexplored, particularly in the more realistic cross-tokenizer setting. The incompatibility of tokenization schemes between teacher and student models has largely prevented fine-grained, white-box distillation of preference information. To address this gap, we propose Cross-Tokenizer Preference Distillation (CTPD), the first unified framework for transferring human-aligned behavior between models with heterogeneous tokenizers. CTPD introduces three key innovations: (1) Aligned Span Projection, which maps teacher and student tokens to shared character-level spans for precise supervision transfer; (2) a cross-tokenizer adaptation of Token-level Importance Sampling (TIS-DPO) for improved credit assignment; and (3) a Teacher-Anchored Reference, allowing the student to directly leverage the teacher’s preferences in a DPO-style objective. Our theoretical analysis grounds CTPD in importance sampling, and experiments across multiple benchmarks confirm its effectiveness, with significant performance gains over existing methods. These results establish CTPD as a practical and general solution for preference distillation across diverse tokenization schemes, opening the door to more accessible and efficient alignment of language models.
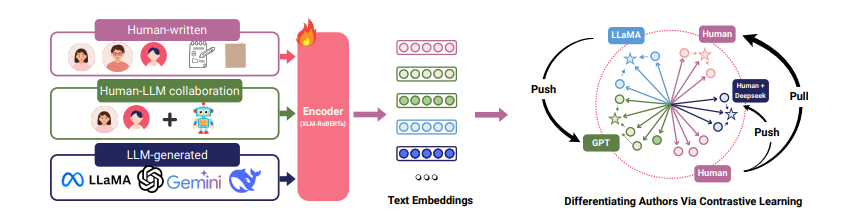
- FAID: Fine-grained AI-generated Text Detection using Multi-task Auxiliary and Multi-level Contrastive LearningMinh Ngoc Ta, Truong Nguyen, Dong Cao Van, and 6 more authorsProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics, 2026
The growing collaboration between humans and AI models in generative tasks has introduced new challenges in distinguishing between \textithuman-written, \textitLLM-generated, and \textithuman-LLM collaborative texts. In this work, we collect a multilingual, multi-domain, multi-generator dataset \textitFAIDSet. We further introduce a fine-grained detection framework FAID to classify text into these three categories, and also to identify the underlying LLM family of the generator. Unlike existing binary classifiers, FAID is built to capture both authorship and model-specific characteristics. Our method combines multi-level contrastive learning with multi-task auxiliary classification to learn subtle stylistic cues. By modeling LLM families as distinct stylistic entities, we incorporate an adaptation to address distributional shifts without retraining for unseen data. Our experimental results demonstrate that FAID outperforms several baselines, particularly enhancing the generalization accuracy on unseen domains and new LLMs, thus offering a potential solution for improving transparency and accountability in AI-assisted writing. Our data and code are available at \urlhttps://github.com/mbzuai-nlp/FAID.